围猎ChatGPT前,华为阿里百度先打一架
2023-04-24
 “大模型”开始扎堆了。
从百度文心一言上线开始算起,一个多月时间内,国内版“大模型”争先恐后,鱼贯而出。
阿里、商汤等大厂的大模型相继问世,已拥有盘古大模型的华为也被唤醒,至于市面上追随文心一言出现的类ChatGPT产品,更是层出不穷。
最新的消息是科大讯飞,5月6日,科大讯飞将正式发布讯飞星火大模型。
阿里巴巴集团董事会主席兼CEO张勇的一句话,或许道出了如今大模型大热的原因:所有产品都值得用大模型重做一遍。
一切仿佛回到那个互联网+模式蒙眼狂奔的时代,自行车、马扎、雨伞、充电宝……一系列原有的事物,在互联网思维的加持下变成了共享单车、共享马扎、共享雨伞、共享充电宝,此后,又在激烈的烧钱大战中优胜劣汰,灰飞烟灭。
如今这一幕,或将又在大模型热中重现。
百度文心一言之前,独领大模型风骚的是ChatGPT,国内公众只有羡慕嫉妒恨的份儿。
文心一言出来后,国内对大模型的讨论、对比、褒贬才显得真切并言之有物起来。
“大模型”开始扎堆了。
从百度文心一言上线开始算起,一个多月时间内,国内版“大模型”争先恐后,鱼贯而出。
阿里、商汤等大厂的大模型相继问世,已拥有盘古大模型的华为也被唤醒,至于市面上追随文心一言出现的类ChatGPT产品,更是层出不穷。
最新的消息是科大讯飞,5月6日,科大讯飞将正式发布讯飞星火大模型。
阿里巴巴集团董事会主席兼CEO张勇的一句话,或许道出了如今大模型大热的原因:所有产品都值得用大模型重做一遍。
一切仿佛回到那个互联网+模式蒙眼狂奔的时代,自行车、马扎、雨伞、充电宝……一系列原有的事物,在互联网思维的加持下变成了共享单车、共享马扎、共享雨伞、共享充电宝,此后,又在激烈的烧钱大战中优胜劣汰,灰飞烟灭。
如今这一幕,或将又在大模型热中重现。
百度文心一言之前,独领大模型风骚的是ChatGPT,国内公众只有羡慕嫉妒恨的份儿。
文心一言出来后,国内对大模型的讨论、对比、褒贬才显得真切并言之有物起来。
 也许时至今日,不少人还在嘲笑百度文心一言有这样那样“胡说八道”的问题。但不少科技从业者已经看到了文心一言背后大模型的力量。
大模型的全称是“预训练通用大模型”,这是一个与“小模型”或“垂直大模型”相对的概念。
早期的人工智能是针对特殊应用场景进行的训练,例如,翻译功能只能用于翻译,画图功能只能用于画图,两者之间并不联通。
大模型的改变在于,通过大量的数据,进行预先的训练,形成一套基础的模型,大量提高人工智能的通用性和实用性。在生成具体的应用时,只需根据应用的需求进行微调即可。
简单来说,大模型就是把海量的食材,经过一定的工序,制作成为各种功能兼具的“食材包”,要端到餐桌上的时候,只需要根据客人的需求,取用食材,按食谱做加工即可。
当ChatGPT席卷全球的时候,拥有大模型的百度,可以迅速依靠大模型拿出一套应用,来对标ChatGPT,并将应用植入到搜索等诸多场景之中。
除了文心一言之外,百度方面还透露,文心已累计发布11个行业大模型,涵盖电力、燃气、金融、航天、传媒、城市、影视、制造、社科等领域。
华为的《预训练大模型白皮书》曾经这样描述预训练大模型的意义,在下一个划时代的计算模型出现之前,预训练大模型将是人工智能领域最有效的通用范式,并将产生巨大的商业价值。
而且,相比于普通开发者从头搭建的算法,其精度明显上升,数据和计算成本明显下降,且开发难度大大降低。以计算机视觉模型为例,其开发成本只相当于原来的10%甚至1%。
这样的机会,没有哪个大厂愿意错过。
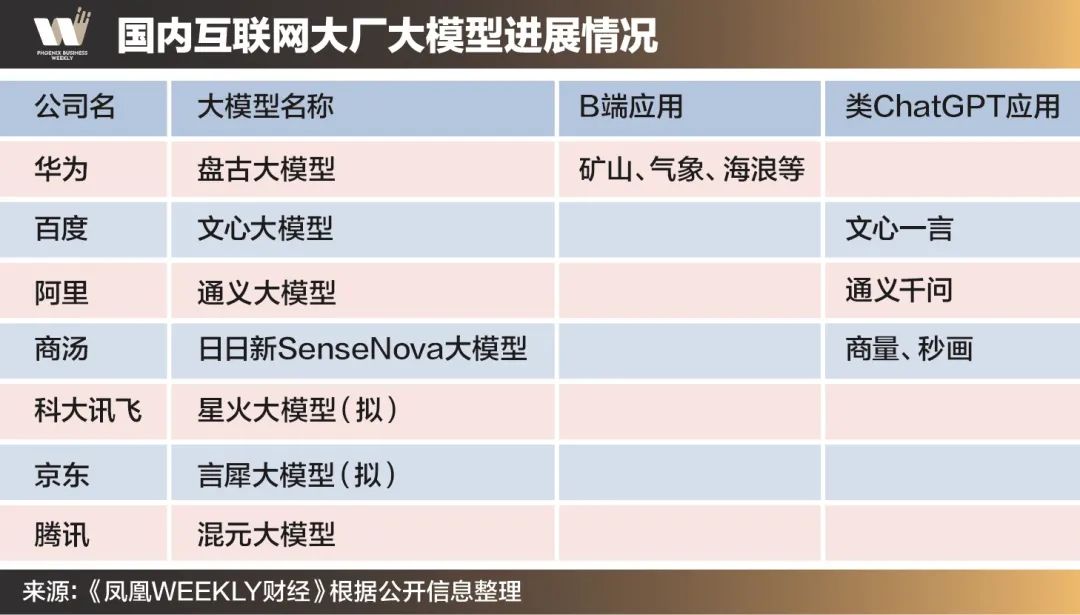
继3月16日百度文心一言发布后,阿里和商汤分别于4月7日和4月10日发布了类ChatGPT产品“通义千问”和“商量SenseChat”,其背后对应的分别是阿里的通义大模型和商汤的日日新SenseNova大模型。
根据民生证券研报统计,目前国内至少已经有30多家大模型亮相,其中不乏参数规模甚至超过ChatGPT规模的大模型。厂商涵盖了互联网巨头、AI上市公司、服务器龙头企业、科研院所与一级市场创业公司。
也许时至今日,不少人还在嘲笑百度文心一言有这样那样“胡说八道”的问题。但不少科技从业者已经看到了文心一言背后大模型的力量。
大模型的全称是“预训练通用大模型”,这是一个与“小模型”或“垂直大模型”相对的概念。
早期的人工智能是针对特殊应用场景进行的训练,例如,翻译功能只能用于翻译,画图功能只能用于画图,两者之间并不联通。
大模型的改变在于,通过大量的数据,进行预先的训练,形成一套基础的模型,大量提高人工智能的通用性和实用性。在生成具体的应用时,只需根据应用的需求进行微调即可。
简单来说,大模型就是把海量的食材,经过一定的工序,制作成为各种功能兼具的“食材包”,要端到餐桌上的时候,只需要根据客人的需求,取用食材,按食谱做加工即可。
当ChatGPT席卷全球的时候,拥有大模型的百度,可以迅速依靠大模型拿出一套应用,来对标ChatGPT,并将应用植入到搜索等诸多场景之中。
除了文心一言之外,百度方面还透露,文心已累计发布11个行业大模型,涵盖电力、燃气、金融、航天、传媒、城市、影视、制造、社科等领域。
华为的《预训练大模型白皮书》曾经这样描述预训练大模型的意义,在下一个划时代的计算模型出现之前,预训练大模型将是人工智能领域最有效的通用范式,并将产生巨大的商业价值。
而且,相比于普通开发者从头搭建的算法,其精度明显上升,数据和计算成本明显下降,且开发难度大大降低。以计算机视觉模型为例,其开发成本只相当于原来的10%甚至1%。
这样的机会,没有哪个大厂愿意错过。
继3月16日百度文心一言发布后,阿里和商汤分别于4月7日和4月10日发布了类ChatGPT产品“通义千问”和“商量SenseChat”,其背后对应的分别是阿里的通义大模型和商汤的日日新SenseNova大模型。
根据民生证券研报统计,目前国内至少已经有30多家大模型亮相,其中不乏参数规模甚至超过ChatGPT规模的大模型。厂商涵盖了互联网巨头、AI上市公司、服务器龙头企业、科研院所与一级市场创业公司。
 还有一个动力,来自于大厂自身。
经历了增速放缓、向内要利润带来的“阵痛”之后,大模型可能是互联网大厂的下一个,也是唯一一个能恢复“狂飙”状态的新领域。
过去一年,伴随着种种原因,大厂们都忙着做减法,不赚钱的业务果断关停,没有前景的项目果断砍掉,给内部试错的机会和时间都越来越少。
这与大厂此前的态度截然不同,对互联网企业来说,只要业务本身健康、赚钱,有毛利,能继续用投入换来商业模式的升级、人员结构的稳定和新的业务产出,净利方面,亏点钱算不得什么。
但一旦大厂进入“要利润”的阶段,同步带来的就是放慢脚步,降本增效,裁员和“毕业”的戏码就会时常上演。
大模型的出现,显然是给大厂指了一条向前“狂飙”的新赛道,既有商业价值,又有成长空间,唯一差的就是投入。
而对互联网大厂来说,只要能看到出路,能讲出故事,以大厂的名头,不愁没钱可烧。
如今的人工智能,刚刚通过OpenAI与ChatGPT看到了商业化的曙光。
除了文心一言应用于搜索之外,阿里的通义千问将目光聚焦在了协同办公。在为数不多的C端应用场景中,搜索、办公这些偏向标准化的场景,是人工智能大模型和人工智能应用最好的用武之地。
4月7日,通义千问的发布会上,阿里已经将钉钉当作了人工智能应用的重要场景。例如,钉钉接入通义千问之后,可以在文档中创作诗歌,撰写邮件、方案等。在会议中,可以生成会议记录,总结会议纪要等。在群聊中,可以自动总结群聊信息中的要点等。
还有一个动力,来自于大厂自身。
经历了增速放缓、向内要利润带来的“阵痛”之后,大模型可能是互联网大厂的下一个,也是唯一一个能恢复“狂飙”状态的新领域。
过去一年,伴随着种种原因,大厂们都忙着做减法,不赚钱的业务果断关停,没有前景的项目果断砍掉,给内部试错的机会和时间都越来越少。
这与大厂此前的态度截然不同,对互联网企业来说,只要业务本身健康、赚钱,有毛利,能继续用投入换来商业模式的升级、人员结构的稳定和新的业务产出,净利方面,亏点钱算不得什么。
但一旦大厂进入“要利润”的阶段,同步带来的就是放慢脚步,降本增效,裁员和“毕业”的戏码就会时常上演。
大模型的出现,显然是给大厂指了一条向前“狂飙”的新赛道,既有商业价值,又有成长空间,唯一差的就是投入。
而对互联网大厂来说,只要能看到出路,能讲出故事,以大厂的名头,不愁没钱可烧。
如今的人工智能,刚刚通过OpenAI与ChatGPT看到了商业化的曙光。
除了文心一言应用于搜索之外,阿里的通义千问将目光聚焦在了协同办公。在为数不多的C端应用场景中,搜索、办公这些偏向标准化的场景,是人工智能大模型和人工智能应用最好的用武之地。
4月7日,通义千问的发布会上,阿里已经将钉钉当作了人工智能应用的重要场景。例如,钉钉接入通义千问之后,可以在文档中创作诗歌,撰写邮件、方案等。在会议中,可以生成会议记录,总结会议纪要等。在群聊中,可以自动总结群聊信息中的要点等。
 这与微软有着相似之处。
就在3月17日,微软已基于ChatGPT,为Office开发出了名叫Copilot的新功能。官网介绍称,在Word中,Copilot能为用户提供初稿以供编辑,能节省写作、找资源和编辑的时间。在PPT中,可以帮助用户通过简单的提示创建演示文稿。在Excel中,可以帮助用户分析数据。
透过ChatGPT生长的土壤,大模型更像是一个超级的App,或者是一个超级底座。
在这个底座基础上,各家科技企业将自己所掌握的人工智能技术,与各行各业的需求结合,训练、生成自己的应用和服务,并通过应用和服务获取收益。
通过这种过程,原则上来说,只要有细分领域数据,大模型就可以针对垂直领域做优化,赋能各行各业。
这意味着,与ChatGPT、文心一言、通义千问等常见的C端应用不同的是,大模型的真正用武之地和赚钱之道,来自于B端。这是互联网“人口红利”增长见顶的当下,大厂们最需要抓住的领域。
商汤科技联合创始人、首席科学家王晓刚在大模型发布活动上表示,商汤版的GPT主要面向企业端(B2B)业务。此外,商汤“日日新SenseNova”大模型体系已全面支持了智能汽车、智慧生活、智慧商业、智慧城市等业务板块,而且商汤将向客户提供涵盖图片生成、自然语言对话、视觉推理和标注服务等API接口。
华为也是如此,华为盘古大模型早在2021年就已经发布,时至今日,华为并未追随文心一言、通义千问等推出偏向C端的应用。
相对而言,华为云AI已经在各行业有超过1000个项目,迄今为止基于盘古大模型,陆续推出了矿山、制药、气象、海浪等大模型。
例如,矿山大模型作为行业类的预训练模型,可以基于采矿业的数据、地质情况,迅速学习矿业知识,进而生成针对不同矿藏的应用,解决井下采矿的智能化、自动化问题。而海浪大模型,则可以根据海洋数据,在渔业等海洋相关的行业内应用,减少人工海上作业的风险。
国金证券研报认为,华为的盘古大模型具备“一个模型在众多场景通用、可泛化和规模化复制”的特点,让AI开发模式由作坊式向工业化转变。
对大厂们来说,一个天然的优势是,大厂自身就通过投资或实际经营涉足了诸多行业,本着“肥水不流外人田”的原则,大厂的自身业务,既可以成为最先享受到人工智能赋能的领域,也是大模型最好的“试金石”。
李彦宏曾经介绍,百度计划将多项主流业务与文心一言整合,涉足的业务包括搜索、百度智能云、Apollo智能舱,以及小度。
这与微软有着相似之处。
就在3月17日,微软已基于ChatGPT,为Office开发出了名叫Copilot的新功能。官网介绍称,在Word中,Copilot能为用户提供初稿以供编辑,能节省写作、找资源和编辑的时间。在PPT中,可以帮助用户通过简单的提示创建演示文稿。在Excel中,可以帮助用户分析数据。
透过ChatGPT生长的土壤,大模型更像是一个超级的App,或者是一个超级底座。
在这个底座基础上,各家科技企业将自己所掌握的人工智能技术,与各行各业的需求结合,训练、生成自己的应用和服务,并通过应用和服务获取收益。
通过这种过程,原则上来说,只要有细分领域数据,大模型就可以针对垂直领域做优化,赋能各行各业。
这意味着,与ChatGPT、文心一言、通义千问等常见的C端应用不同的是,大模型的真正用武之地和赚钱之道,来自于B端。这是互联网“人口红利”增长见顶的当下,大厂们最需要抓住的领域。
商汤科技联合创始人、首席科学家王晓刚在大模型发布活动上表示,商汤版的GPT主要面向企业端(B2B)业务。此外,商汤“日日新SenseNova”大模型体系已全面支持了智能汽车、智慧生活、智慧商业、智慧城市等业务板块,而且商汤将向客户提供涵盖图片生成、自然语言对话、视觉推理和标注服务等API接口。
华为也是如此,华为盘古大模型早在2021年就已经发布,时至今日,华为并未追随文心一言、通义千问等推出偏向C端的应用。
相对而言,华为云AI已经在各行业有超过1000个项目,迄今为止基于盘古大模型,陆续推出了矿山、制药、气象、海浪等大模型。
例如,矿山大模型作为行业类的预训练模型,可以基于采矿业的数据、地质情况,迅速学习矿业知识,进而生成针对不同矿藏的应用,解决井下采矿的智能化、自动化问题。而海浪大模型,则可以根据海洋数据,在渔业等海洋相关的行业内应用,减少人工海上作业的风险。
国金证券研报认为,华为的盘古大模型具备“一个模型在众多场景通用、可泛化和规模化复制”的特点,让AI开发模式由作坊式向工业化转变。
对大厂们来说,一个天然的优势是,大厂自身就通过投资或实际经营涉足了诸多行业,本着“肥水不流外人田”的原则,大厂的自身业务,既可以成为最先享受到人工智能赋能的领域,也是大模型最好的“试金石”。
李彦宏曾经介绍,百度计划将多项主流业务与文心一言整合,涉足的业务包括搜索、百度智能云、Apollo智能舱,以及小度。
 张勇也表示,阿里巴巴所有产品,包括天猫、钉钉、高德地图、淘宝、优酷、盒马等,未来都将接入“通义千问”大模型进行改造。
大模型之争,才开了个头,大戏还在后头。
华为《预训练大模型白皮书》中指出,通过大模型构筑AI技术竞争壁垒,是当前中美AI技术竞争的热点。
围绕大模型的竞争,不外乎两个因素:财力和算力。
毋庸置疑,大模型是一项极为烧钱的事物。
《财经十一人》援引多位技术人士的观点总结称,大模型的投入成本包括,一个智算集群的建设成本约30亿元,一次完整的模型训练成本少则千万元,多则上亿元。这还没算数据采集、网络带宽、电费等成本,也有数亿元的开销。
此前有消息称,微软仅仅是在ChatGPT-3的训练中,就投入了1200万美元。而OpenAI在过去一年中烧掉了5亿美元。
张勇也表示,阿里巴巴所有产品,包括天猫、钉钉、高德地图、淘宝、优酷、盒马等,未来都将接入“通义千问”大模型进行改造。
大模型之争,才开了个头,大戏还在后头。
华为《预训练大模型白皮书》中指出,通过大模型构筑AI技术竞争壁垒,是当前中美AI技术竞争的热点。
围绕大模型的竞争,不外乎两个因素:财力和算力。
毋庸置疑,大模型是一项极为烧钱的事物。
《财经十一人》援引多位技术人士的观点总结称,大模型的投入成本包括,一个智算集群的建设成本约30亿元,一次完整的模型训练成本少则千万元,多则上亿元。这还没算数据采集、网络带宽、电费等成本,也有数亿元的开销。
此前有消息称,微软仅仅是在ChatGPT-3的训练中,就投入了1200万美元。而OpenAI在过去一年中烧掉了5亿美元。
 以微软过去一年727.38亿美元的净利润来透视,这笔投入尚在能负担得起的范畴。而放到国内,既有资金实力,又有云业务作为基础的企业,也就是华为、百度、阿里、腾讯等少数几家头部互联网大厂。至于现在才刚刚开始投入大模型的创业者,能扛到最后的概率更是非常渺小的。
除了钱之外,算力方面,中国也处在“卡脖子”的阶段。代表着算力最高性能的英伟达A100和H100芯片被限制向中国出售,能够获得的最佳替代品A800也处在供不应求的状态。
这样的劣势,会带来AI大模型训练的准确度和反应速度都不足。反映到具体的应用中,就体现为文心一言、通义千问的“智商”远低于ChatGPT。
财力和算力都不占优,中国企业唯一可能有所作为的,是数据。这也是每一家大厂的看家宝贝。
伴随着“所有产品都值得用大模型重做一遍”的口号,另一个可能出现的现象是“所有的数据壁垒也都会在大模型上重建一遍”。
很多人或许还能想起,互联网巨头们画地为牢,搭建起一个个生态孤岛的时代。微信无法分享淘宝链接,淘宝也不能使用微信支付,用户、数据、基础设施和信息的自由流动都因此割裂开来。
如今,互联互通的时代早已来临,但大模型之于当今各行各业的意义,仍然与早年间支付宝、微信的意义相差无几。对于拥有大量数据的互联网大厂来说,无外乎两条路,要么下场砸钱,做出属于自己的通用大模型,或至少是针对细分领域的垂直大模型;要么乖乖将自己的数据捧到别家大模型的手里。
国盛证券研报认为,即使大模型已经拥有强大智能,但可能缺乏特定场景的知识,也需要结合具体场景的需求,因此在落地时依然需要场景数据进行微调。
换句话说,有了大模型,就有了吸取各行各业数据的入口,也会在智能化水平、赋能水平上形成自己的护城河,高出其他没有大模型的厂商一头。
因此,才有了脉脉创始人林凡爆料称,“ChatGPT带动的AIGC创业热潮要来了,猎头已经开出10万月薪抢人。”以及,不少人工智能企业都释放出岗位,争抢最顶级的算法工程师。
但更重要的是,从国内的视野来看,大模型的商业化落地尽管有了部分进展,例如华为依托盘古大模型训练出来的矿山大模型已经在山东的能源企业得到应用,但总体而言,大模型的商业化落地并不稳定,不足以拿出去给外人看。更多的企业还是在像百度文心一言上线初期一样,处在疯狂“摇人”测试性能的阶段。
有业内人士认为,这种疯狂的创立大模型,训练大模型的窗口期不会太长,最多半年到一年,就会有出局者诞生。但大模型真正带来稳定的商业化落地,改变各行各业,形成新的生态,为互联网企业带来稳定的收益,还需要更长的时间。
由此看来,烧钱的战事,才刚刚开始。
本文来自微信公众号“凤凰WEEKLY财经”(ID:fhzkzk),作者:张轶骁,36氪经授权发布。
以微软过去一年727.38亿美元的净利润来透视,这笔投入尚在能负担得起的范畴。而放到国内,既有资金实力,又有云业务作为基础的企业,也就是华为、百度、阿里、腾讯等少数几家头部互联网大厂。至于现在才刚刚开始投入大模型的创业者,能扛到最后的概率更是非常渺小的。
除了钱之外,算力方面,中国也处在“卡脖子”的阶段。代表着算力最高性能的英伟达A100和H100芯片被限制向中国出售,能够获得的最佳替代品A800也处在供不应求的状态。
这样的劣势,会带来AI大模型训练的准确度和反应速度都不足。反映到具体的应用中,就体现为文心一言、通义千问的“智商”远低于ChatGPT。
财力和算力都不占优,中国企业唯一可能有所作为的,是数据。这也是每一家大厂的看家宝贝。
伴随着“所有产品都值得用大模型重做一遍”的口号,另一个可能出现的现象是“所有的数据壁垒也都会在大模型上重建一遍”。
很多人或许还能想起,互联网巨头们画地为牢,搭建起一个个生态孤岛的时代。微信无法分享淘宝链接,淘宝也不能使用微信支付,用户、数据、基础设施和信息的自由流动都因此割裂开来。
如今,互联互通的时代早已来临,但大模型之于当今各行各业的意义,仍然与早年间支付宝、微信的意义相差无几。对于拥有大量数据的互联网大厂来说,无外乎两条路,要么下场砸钱,做出属于自己的通用大模型,或至少是针对细分领域的垂直大模型;要么乖乖将自己的数据捧到别家大模型的手里。
国盛证券研报认为,即使大模型已经拥有强大智能,但可能缺乏特定场景的知识,也需要结合具体场景的需求,因此在落地时依然需要场景数据进行微调。
换句话说,有了大模型,就有了吸取各行各业数据的入口,也会在智能化水平、赋能水平上形成自己的护城河,高出其他没有大模型的厂商一头。
因此,才有了脉脉创始人林凡爆料称,“ChatGPT带动的AIGC创业热潮要来了,猎头已经开出10万月薪抢人。”以及,不少人工智能企业都释放出岗位,争抢最顶级的算法工程师。
但更重要的是,从国内的视野来看,大模型的商业化落地尽管有了部分进展,例如华为依托盘古大模型训练出来的矿山大模型已经在山东的能源企业得到应用,但总体而言,大模型的商业化落地并不稳定,不足以拿出去给外人看。更多的企业还是在像百度文心一言上线初期一样,处在疯狂“摇人”测试性能的阶段。
有业内人士认为,这种疯狂的创立大模型,训练大模型的窗口期不会太长,最多半年到一年,就会有出局者诞生。但大模型真正带来稳定的商业化落地,改变各行各业,形成新的生态,为互联网企业带来稳定的收益,还需要更长的时间。
由此看来,烧钱的战事,才刚刚开始。
本文来自微信公众号“凤凰WEEKLY财经”(ID:fhzkzk),作者:张轶骁,36氪经授权发布。
© 版权声明
本文转载自互联网、仅供学习交流,内容版权归原作者所有,如涉作品、版权或其它疑问请联系删除。
 京公网安备
2022012259号
京公网安备
2022012259号